
The Onchain Inference Trade
The inference cycle is running. Decentralized providers have carved moats in the three places Web2 cannot go.

TL;DR
- OpenRouter processed over 12 trillion tokens per week by early 2026, up 12x year on year (per OpenRouter / a16z State of AI report, Dec 2025). Falling inference costs expand the market via Jevons’ Paradox which is what makes the trade compelling.
- Decentralized inference providers have real ARR (~$12-14M Venice, ~$6M Chutes) and three structural moats Web2 cannot replicate: privacy, uncensored AI, and a 70-85% pricing advantage.
- Most revenue is still token-subsidized (Chutes ~90% subsidy ratio is worse than the Helium 78% DePIN benchmark). Organic economics at scale are not yet proven.
- Galaxy Digital’s formal institutional report is in production and unpublished. The window for early positioning is open.
- Core: $VVV, $AKT. Higher beta: $TAO, $POD. Farm: Ritual, Inference Labs.
Conviction Tier: MEDIUM CONVICTION
Upgrades to HIGH CONVICTION on enterprise-scale production deployment confirmation from at least one major protocol, OR organic revenue covering more than 50% of total protocol revenue without token subsidies.
PMF is confirmed (Venice ARR, Chutes OpenRouter #1 ranking, DIEM perpetual credit adoption). Tokenomics innovation is real. Pricing moat is structural. Risks are specific and named: subsidy dependency is the primary one, TAO halving pressure is real, Venice centralization debate is unresolved, enterprise scale remains unproven. Size these positions relative to those risks.
Introduction
OpenRouter grew from ~10 trillion tokens processed annually to over 100 trillion as of mid-2025. By early 2026, the platform was handling over 12 trillion tokens per week, a 12x increase YoY (per OpenRouter / a16z State of AI report, Dec 2025). The standard read is that inference is becoming a commodity, costs are collapsing, and that is structurally bad for any provider operating in the space. That read has it backwards, and completely misses the point.
When a resource gets 10x cheaper and usage grows 30x in response, you are not watching margin compression. You are watching Jevons’ Paradox operate at the scale of global infrastructure. The inference market is not contracting as costs fall. It is expanding faster than any model projected, and the protocols positioned in the correct structural slots are compounding into something that has not been formally covered by a single major research institution.
That institutional gap is where this piece sits. Galaxy Digital’s Research Associate Lucas Tcheyan publicly signalled a formal research pivot to decentralized inference in May 2026, soliciting project names for inclusion in a forthcoming report. That report is not yet published. What follows is a synthesis of where the category stands, who the leaders are, and what the real risks look like before that coverage arrives.
The Structural Shift
The history of AI access can be told in three phases.
The first was closed AI: expensive, proprietary, censored. Built by OpenAI, Anthropic, and Google on centralised infrastructure, accessible through APIs with content restrictions and data logging baked into the architecture. The pricing reflected the monopoly on both intelligence and distribution.
The second was open AI (not the company ironically): The release of Llama, Mistral, and DeepSeek created commoditised base intelligence. Open-weight models collapsed the cost of raw capability. The question that emerged from this phase was not who could build AI, but who would serve it at scale, to whom, and under what terms.
The third phase, which is where we are now, is decentralized AI: Token emissions fund research teams without dilutive venture rounds. Idle consumer GPUs yield inference revenue. Distributed compute networks source capacity at ~70-85% below AWS SageMaker pricing and pass that discount to developers routing inference requests at machine speed through agent harnesses running billions of API calls per session.
The transition from the second phase to the third is not hypothetical. Tools built on top of open-weight models were burning billions of inference tokens daily before major closed labs moved to restrict automated harness usage. That restriction, widely read as bearish for inference demand, is structurally bullish for the decentralized layer. When closed labs restrict access, developers migrate to open-weight models on decentralized rails that carry no content policy. The demand does not disappear. It relocates. This is the thesis, as well as the premise of this piece.
The Business Model
The unit economics of a decentralized inference provider are worth understanding precisely, because they are the structural source of the advantage.
Cutting away the jargon, the whole workflow can be written and understood in a few simple steps:
Source compute from a decentralized cloud marketplace at ~70-85% below AWS SageMaker pricing.
Host open-weight and private AI models at that cost basis.
Charge developers via API subscriptions or usage fees that are still materially cheaper than OpenAI or Anthropic.
Capture the spread. Then layer in token mechanics that create switching costs no centralised provider can replicate.
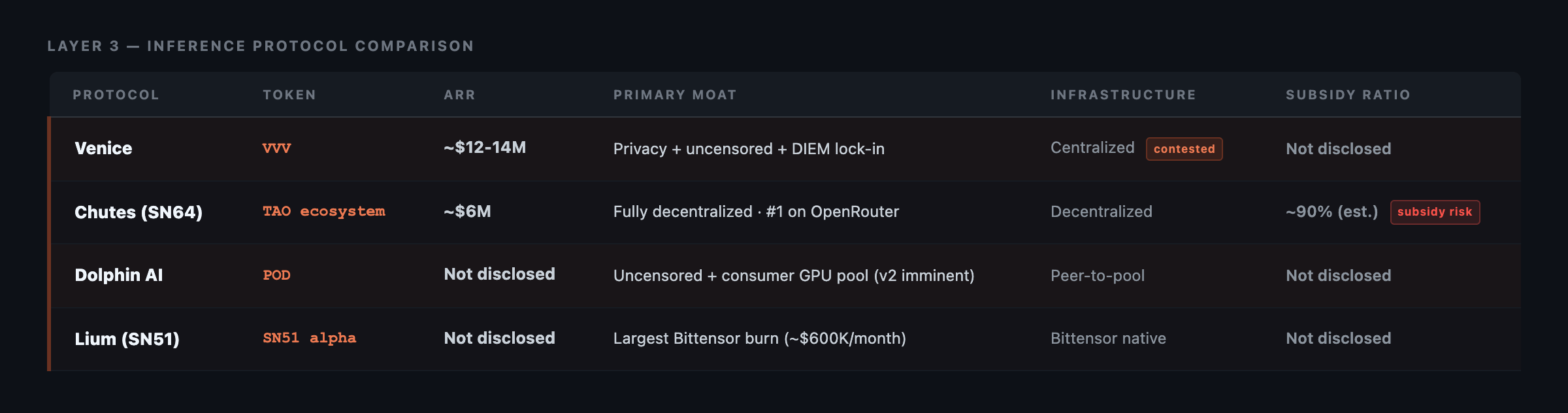
The two clearest executions of this model are Venice AI and Chutes.
Venice AI ($VVV)
Venice AI is running ~$12-14M in annual recurring revenue on 50-80B tokens per day, with a single-day peak of 80B tokens, per platform analytics at venicestats.com.
The tokenomics innovation that matters specifically for Venice is DIEM. Here’s how it works in practice; Stake $VVV, earn approximately 18% APY, and mint DIEM tokens. Each DIEM token generates one dollar per day in Venice inference credits, indefinitely.
This is not a governance token or a speculative instrument in the traditional sense. It is a perpetual inference credit: DeFi yield mechanics applied to AI compute. Capital staked into Venice cannot be easily withdrawn without unwinding a position generating daily yield. That lock-in is by design. The Pendle and Penpie analogy from DeFi explain this choice by Venice precisely: PT/YT leverage markets and governance arbitrage on inference credit bribe markets will follow as the ecosystem matures.
Chutes (Subnet 64, Bittensor Ecosystem Project)
Chutes, built on Bittensor Subnet 64, is running ~$6M ARR on comparable token volume, ranked number one on OpenRouter for decentralised inference as of May 2026.
The distinction from Venice is structural: Chutes is fully decentralized, with no centralised infrastructure critique applicable to it. Its subsidy ratio, however, sits at an estimated ~90% i.e. in simple words, nine in every ten dollars of revenue is token-subsidised, not organically generated. This exceeds even Helium’s 78% benchmark at a comparable stage of the DePIN cycle. That distinction matters significantly for the bear case, which I address directly below.
Per ETH Denver benchmarks from February 2026, the decentralized inference segment was already at ~$20-30M ARR across Bittensor subnets, against a subnet market cap of ~$212M. For reference, the broader DePIN sector was generating $72M in revenue against $10B in market cap at the same timeframe. The decentralized inference sub-sector is generating comparable revenue at a fraction of the market cap assigned to DePIN broadly.
That should tell you how early we are in the narrative cycle despite the ~8x pump recorded by VVV token in the past few weeks.
The Stack
Five distinct layers form the decentralized AI inference supply chain. Each carries different maturity, different tokenomics design, and different risk profiles.
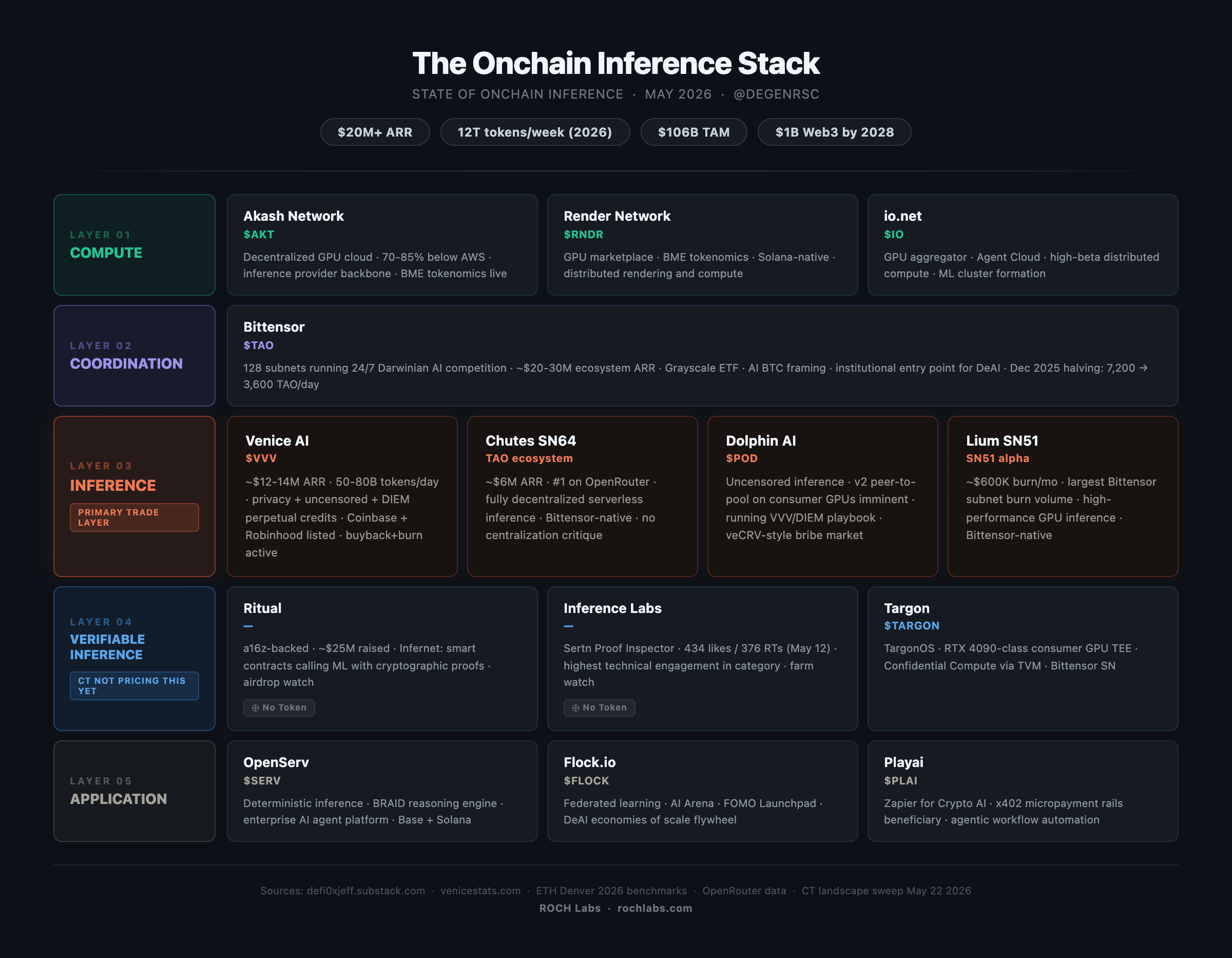
The Compute layer
Akash Network ($AKT) is the primary decentralized GPU marketplace, the infrastructure backbone from which most inference providers source capacity. Burn-and-mint emissions tokenomics are live for $AKT. Render Network ($RNDR) and io.net ($IO) serve adjacent compute demand across the same structural thesis.
This is the pick-and-shovel layer: every inference provider that scales through decentralized compute builds on top of it.
The Coordination layer
This is where Bittensor ($TAO) sits on the whole map. Its 128 subnets run in continuous Darwinian competition for resources, talent, and inference share. Grayscale has taken stakes in TAO and is building ETF products around the asset.
The framing that has taken hold institutionally is “TAO is the BTC of AI,” a macro-levered coordination layer providing diversified exposure to the entire decentralized AI stack. At ~$20-30M in ecosystem ARR, it is the most levered expression of the category thesis.
The Inference layer
This is where primary value accrual is happening now. Venice and Chutes lead the current cycle. Lium on Bittensor Subnet 51 is generating ~$600K in monthly burn volume, the largest of any Bittensor subnet. Dolphin AI ($POD) is executing Venice’s tokenomics playbook on consumer GPU infrastructure, with its v2 peer-to-pool network imminent.
The Verifiable Inference layer (a sub-segment for now, but a full segment eventually) is the one the market is not pricing. I return to this in the moats section below.
The Application layer
This covers AI agents, DeFAI, and tooling infrastructure. This is where end-user value accrual eventually concentrates, but where most token fundamentals remain weak relative to the infrastructure layers above them.
The Four Moats
Four structural reasons explain why decentralized inference holds territory that centralised labs cannot enter regardless of capital or compute resources. Below I breakdown exactly what makes them special, and defensible against large centralized incumbents:
Privacy:
Per Cisco’s 2024 Consumer Privacy Survey, 84% of GenAI users are concerned about data entered in tools going public. For enterprise customers operating under GDPR, CCPA, HIPAA, and financial data regulations, this is not a preference item. It is a liability constraint.
OpenAI and Anthropic are structurally compelled to log user interactions for model improvement, abuse detection, and compliance auditing. They cannot offer genuine data separation without dismantling their core model improvement pipelines.
Venice AI, Dolphin AI, and the TEE-stack protocols own this market by structural default. The demand is not niche: enterprise legal, healthcare, and financial services clients all face mandates that make inference-with-logging a material compliance exposure.
Uncensored AI:
Centralised labs face advertiser sensitivity, regulatory exposure, and reputational risk from uncensored model outputs. Companion AI, penetration testing, red-teaming, political speech in jurisdictions with content restrictions, and enterprise internal tooling with sensitive subject matter are categories the closed labs are structurally blocked from serving at scale.
Venice and Dolphin AI sit permanently on the open-weight side of this divide. As model liability frameworks mature and the market split between compliant-censored and open-weight uncensored AI sharpens, this moat deepens rather than narrows.
Pricing:
AkashML inference costs ~$2-4 per million tokens. OpenAI’s API runs ~$15 per million tokens on GPT-class model output; 2026 flagship models range from $2.50 to $30 per million tokens depending on model and token direction.
The 70-85% structural discount to AWS is not promotional: it derives from idle consumer GPU supply at near-zero marginal cost of capital, token emission subsidies covering infrastructure overhead, and no centralised data centre CAPEX on the balance sheet.
The margin structure improves as the network scales. This is the directional opposite of a traditional cloud provider’s cost curve, and it is the structural basis for the lock-in mechanics described in the business model section above.
Verifiable Inference:
This is the fourth moat and the least understood. TEE-backed inference with cryptographic attestations produces a proof that a specific model generated a specific output, without revealing the model’s weights or the user’s input data.
For autonomous agents executing financial transactions on-chain, the inference output is the instruction. Without cryptographic proof, that instruction is trusted. With it, it is verified.
Ritual, backed by Archetype with ~$25M raised, is building Infernet: smart contracts that natively call ML models with cryptographic proofs. Inference Labs shipped Sertn’s Proof Inspector in May 2026, generating the highest-engagement technical post in the category that month. Neither has a token.
The narrative has not produced a breakout yet, and that’s understable since we haven’t seen a breakout success, or proof it can work at scale, or has any specific enterprise deals tied to it yet. Despite that, verifiable inference is arguably the most defensible structural moat in the stack and is currently trading at the lowest awareness premium of the four.
The Bear Case
The honest version of this thesis requires stating four risks that could break the thesis around decentralized inference, and make this whole thesis stale. Below I break down each one of them:
Dependency Risk:
Chutes is running an estimated ~90% subsidy ratio which means nine in every ten dollars of revenue is token-subsidised, not organically generated. This exceeds even Helium’s 78% benchmark from the DePIN cycle, which was itself considered alarming at the time.
Most decentralized inference revenue is still token-subsidised rather than organically generated. If token prices fall, compute subsidies shrink, the pricing advantage narrows, and users with no structural switching costs have limited reasons to remain.
No protocol in this stack has proven sustainable organic unit economics at scale. That is not a minor caveat. It is the foundational question the thesis must answer to convert from speculative to durable.
The TAO halving risk:
This one is specifically for Bittensor-native projects. Daily emissions were cut from 7,200 to 3,600 TAO in December 2025. Subnet miners whose incentives fall below compute cost break-even will exit.
The Pareto distribution of subnet quality means a significant portion face meaningful pressure. Inference subnets with real revenue are better insulated than meme subnets, but the halving risk is present across the ecosystem and the 60-day churn data post-halving is the primary risk variable to monitor.
Venice’s centralisation critique:
The argument that Venice runs on centralised infrastructure with a decentralised token wrapper is not a fringe position.
If regulatory pressure tightens around centralised AI infrastructure operating with decentralised tokenomics, Venice faces a structural exposure that Chutes, by architecture, does not.
Lopsided demand curve:
Demand is still scarce relative to supply. Significant capital has been deployed into decentralized AI infrastructure. Institutions are running pilots, not production workloads.
No enterprise-scale production deployment is confirmed for any protocol in this stack. The category’s revenue is real. The scale at which it needs to operate to justify current market caps requires enterprise adoption that has not arrived.
What to Watch
Three developments will determine whether this thesis upgrades from its current state to full institutional validation.
The Galaxy Digital decentralized inference report is the most important near-term catalyst. When it publishes, it will be the first institutional-grade research document formally scoped to this category. The historical pattern in crypto is consistent: when the first serious institutional report drops on a category with real fundamentals, narrative velocity accelerates regardless of price action at the time of publication. The pre-publication window is where asymmetric positioning has historically been available.
The Dolphin AI v2 launch is the nearest product catalyst: If the peer-to-pool consumer GPU inference network ships with an early ARR trajectory comparable to Venice’s first months, it validates the hypothesis that the Venice tokenomics model is replicable at scale on distributed consumer hardware, not just enterprise GPU pools sourced from Akash. That would expand the addressable inference supply significantly and harden the pricing moat thesis.
The verifiable inference narrative is the sleeper catalyst: Ritual and Inference Labs have no tokens and no major account has published a dedicated analysis. When the first significant thread or research note covers cryptographic proof of inference at scale, the protocols in this layer will attract pre-token positioning attention. The farming window for those positions exists now, before that awareness arrives.
The TAO halving subnet survival data is the ongoing risk monitor: If churn is manageable and inference subnets with real revenue hold their miner bases over the next 60 days, the halving becomes a supply shock narrative for TAO. If churn is severe, it partially invalidates the Bittensor coordination layer thesis at current prices. It will be interesting to watch how this plays out.
In Conclusion
The 12x expansion in OpenRouter token consumption in a single year is not a growth rate. It is evidence of a structural transition in how the world processes intelligence (per OpenRouter / a16z State of AI report, Dec 2025). The protocols serving that demand from the positions the large labs cannot occupy (private compute, uncensored inference, cutthroat pricing, cryptographic verification) are already generating real revenue, and the suits don’t even know as the institutional research coverage has not arrived yet!
That combination rarely persists. The window between confirmed product-market-fit and institutional narrative is historically short once the first formal report drops. The question is not whether decentralized inference is a real sector: the revenue data answers that. The question is whether the subsidy dependency resolves before the institutional wave fully prices the category.
That is the risk. And it is worth taking seriously before dismissing either the thesis or the bear case that sits underneath it.
Sources
Fact-checked as of 22-May-2026
- Ritual $25M raise — Archetype lead (https://cointelegraph.com/news/ai-infrastructure-startup-ritual-raises-25-m-gaps-crypto)
- Lucas Tcheyan, Research Associate, Galaxy Digital (https://theorg.com/org/galaxy-digital/org-chart/lucas-tcheyan)
- Cisco 2024 Consumer Privacy Survey (https://www.cisco.com/c/dam/en_us/about/doing_business/trust-center/docs/cisco-consumer-privacy-report-2024.pdf)
- OpenAI API Pricing 2026 (https://openai.com/api/pricing/)
- Akash Network GPU pricing (https://akash.network/pricing/gpus/)
- Bittensor halving December 12, 2025 (https://blog.mexc.com/news/bittensors-historic-first-halving-starts-december-12-will-tao-rally-to-1000-as-daily-emissions-drop-50/)
- Grayscale TAO ETF filing (https://phemex.com/news/article/grayscale-files-for-bittensor-etf-stabilizing-tao-price-51072)
- VVV Robinhood listing May 19, 2026 (https://www.cryptotimes.io/2026/05/20/venice-token-vvv-rockets-24-as-robinhood-listing-ignites-rally/)
- Venice AI: Programmatic Buy & Burns (https://venice.ai/blog/programmatic-vvv-buy-and-burn)
- Bittensor subnet ARR: Unsupervised Capital (https://www.unsupervised.capital/writing/bittensors-ai-compute-subnets-collectively-reach-20m-arr)
- OpenRouter / a16z State of AI report (Dec 2025): token consumption data (https://openrouter.ai/state-of-ai)
- OpenRouter weekly token data context - Trending Topics (https://www.trendingtopics.eu/chinese-ai-models-overtake-us-rivals-in-global-token-consumption/)